I Built the Same Product Twice, 14 Years Apart. Here's the Pattern Nobody Names.
August 18, 2012. First commit. A Python script called awsdeploy.
Pearson's CIO had given a simple directive: take us to the cloud. I was a software architect. The immediate problem was deploying MongoDB to AWS without doing it by hand every time.
So I wrote a script.
Three months later that script had a name: Nibiru. A full self-service platform with a Flask web UI, a REST API, Puppet configuration management, Zabbix monitoring, Route 53 DNS, and an LDAP-backed inventory. Every node in the system followed a naming convention I designed: use1a-pri-mongodb-s1-01. Region, environment, service, shard, instance number.
Infrastructure that documented itself.
In 2014 I wrote about what we built. The screenshots are still live. Push-button deployment. Instance JSON. A dashboard serving 70 development teams across three AWS regions. You can read it here.
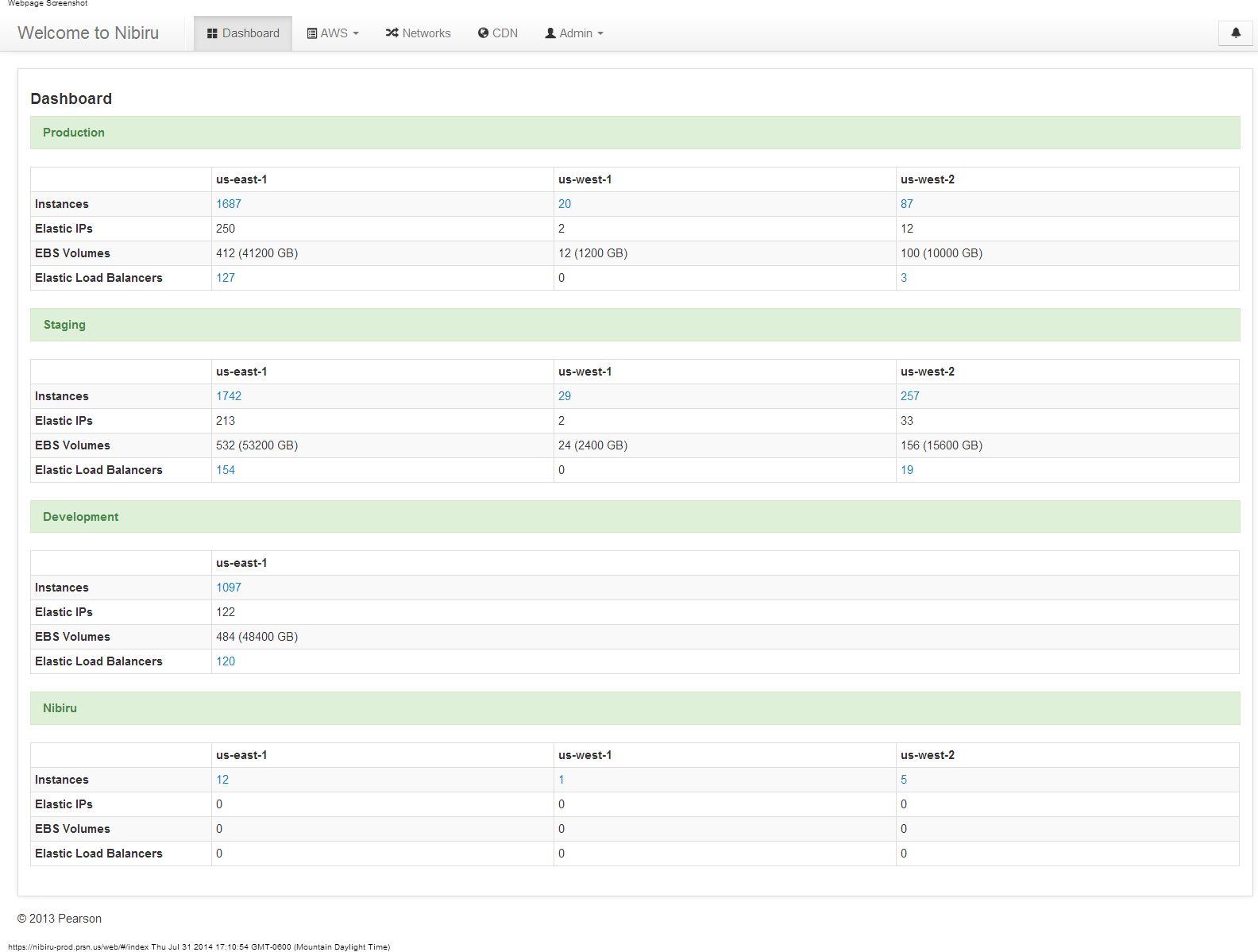
The Nibiru dashboard, 2014. Push-button deployment for 70 development teams.
Last year I pulled the old repos out of GitHub and had Claude Code read all 173 commits.
Its summary: “This was seriously ahead of its time. You basically built a self-service deployment platform with a web UI and REST API years before Terraform, Kubernetes, or even AWS CloudFormation matured.”
Then it compared Nibiru to what I'm building now.
“OutcomeOps and Nibiru are spiritually the same product, just 14 years apart.”
It was right. And the reason that observation matters is not nostalgia. It's because the pattern that made Nibiru work is the same pattern that makes OutcomeOps work, and most organizations building AI tooling right now are skipping it entirely.
What Nibiru Actually Was: An Organizational Intelligence Platform
The surface reading of Nibiru is automation. That misses the point.
The real innovation was opinionated automation. Every architectural decision was encoded into the platform itself so developers could not accidentally violate it.
Take security groups. I had seen complex designs where every database, web server, and product line had its own security group. We did the opposite. Two security groups. Public and private. That was it.
The result: every application in the environment ran on standard ports. Not because we wrote a rule that said so. Because the platform made the right path the only easy path.
Take the Puppet ENC. We needed a way to programmatically assign configuration classes to nodes as they were being created. Nothing available solved it the way we needed, so we built our own with a MongoDB backend. Every node had a defined set of base classes: monitoring, security, logging, backup. Development teams could add optional modules like NodeJS or MongoDB, but they could not remove the defaults. The guardrails were structural.
Take the naming convention. use1a-pri-mongodb-s1-01. Not aesthetic. Queryable. You could look at any instance name and know exactly what it was, where it ran, what environment it served, and how it related to other nodes. The organizational knowledge was baked into the system, not written in a wiki that would be out of date in six months.

Every node carried structured metadata. The system documented itself.
This is what I mean when I say Nibiru was an organizational intelligence layer, not a deployment tool. The platform carried the institutional memory. New engineers did not read runbooks. They opened the dashboard and understood the standards because the standards were enforced structurally.
By the time we were done, months of manual provisioning had become minutes. 70 development teams across the globe were deploying their own infrastructure without opening a ticket.
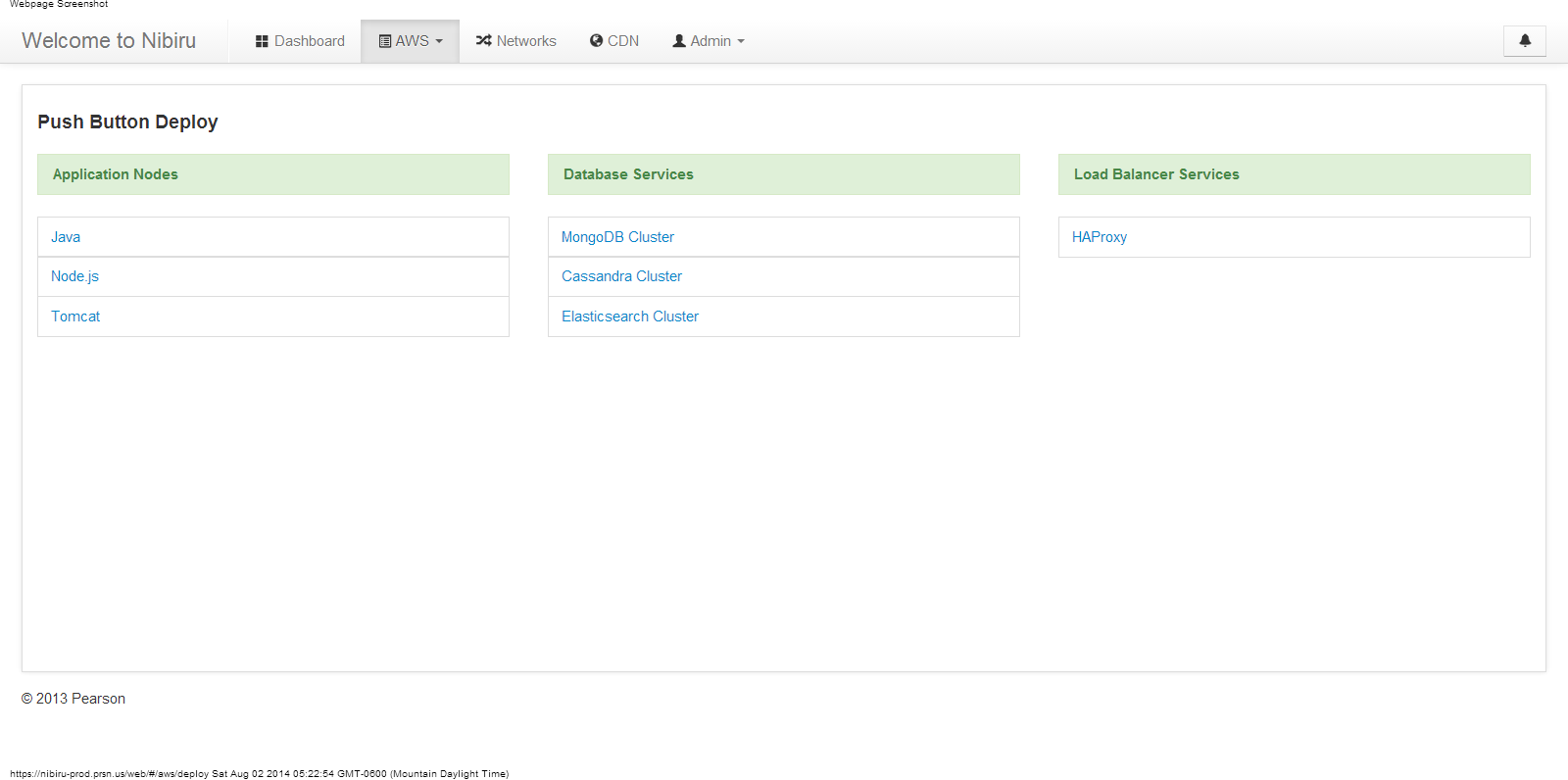
Push-button deployment. No tickets. No gatekeepers.
I Wrote This Argument Before. Twice.
In 2015 I published a post called “Why Traditional IT Organizations Don't Scale.” The argument was about VMware, Mesosphere, Kubernetes, and CloudFoundry.
“Products like VMware, Mesosphere, Kubernetes, and CloudFoundry are great — they provide ‘flexibility,’ a word which sounds great in a marketing pitch but should give any seasoned IT professional the willies. Because ‘flexibility’ is just another word for ‘snowflake.’”
The only way infrastructure organizations scale, I argued, is by taking their business logic, their standards, their naming conventions, their environment promotion rules, and encoding them into an abstraction layer. Not documenting them. Not training people on them. Encoding them into a system that enforces them automatically.
In 2018 I wrote that DevOps initiatives fail because infrastructure teams manage work as projects instead of building products. I used Nibiru as the example of what a product-oriented infrastructure team actually looked like: a product owner, a feature backlog, real stakeholders, consumable output.
The argument in both posts is the same argument. The tools change every few years. The failure mode does not.
What Changed in 14 Years: The Layer, Not the Problem
The layer changed. The problem did not.
In 2012 the unbounded variable was infrastructure. Every team provisioned servers differently. Institutional knowledge about how to do it right lived in senior engineers' heads and evaporated every time one of them left.
In 2026 the unbounded variable is code. Every team is using AI differently. Institutional knowledge about how to write code that matches your organization's standards lives in senior engineers' heads and produces nothing but review comments when AI ignores it.
GitHub Copilot does not know your authentication layer. Claude does not know the API you deprecated in 2019. ChatGPT will suggest patterns your CISO banned in the last audit. Every AI tool generates plausible code against an imaginary codebase, not your actual one.
The production incidents from AI-suggested code look the same as the configuration drift incidents from manual provisioning a decade ago. Different surface. Identical root cause. The organizational knowledge was never encoded into the system.
The critique I made about Kubernetes in 2015 applies to Copilot and Cursor in 2026 word for word. “Flexibility” is still just another word for snowflake. The tool is not the problem. The missing abstraction layer is the problem.
The Context Engineering Pattern That Always Wins
Every generation of tooling starts the same way: give individuals the ability to go faster. The velocity gains are real. Then the problems surface.
Local optimization at scale creates waste. One team spends two sprints wiring AI to understand their codebase. Another team does the same thing simultaneously. Neither knows the other exists. Neither captures what works. Both reinvent context injection from scratch, every sprint, indefinitely. In LEAN terms this is sub-optimization waste — each team optimizing their piece without considering the whole.
The teams that win are never the ones who adopted the tools first. They are the ones who encoded organizational intelligence into the tooling layer.
In 2012 that meant Puppet ENCs and naming conventions. In 2014 at Aetna that meant golden pipelines with a 0.05% security defect density when the enterprise average was 5%. The CISO made Docker a corporate mandate. In 2019 at Comcast that meant SEED, a platform that eliminated the need for engineering teams to write Terraform at all. Zero Terraform required. Dev to prod in minutes.
The philosophy never changed across any of those engagements: make the right path the easy path. Encode the standards into the system so developers cannot accidentally violate them. Replace gatekeepers with guardrails.
OutcomeOps applies that principle to AI code generation.
ADRs and code-maps feed into a vector store. When AI generates code, it queries your organizational knowledge first. Your authentication patterns. Your compliance requirements. Your architectural decisions. The code it generates follows your standards not because you pasted them into a prompt, but because your standards are part of its context at generation time.
The Puppet ENC was 2012's version of this. A structured, queryable, opinionated store of organizational knowledge that shaped every output the system produced. I just did not have the vocabulary for it yet.
I have it now. We call it Context Engineering.
What the Metrics Say
At the Fortune 500 hospitality company where OutcomeOps is running in production:
Same pattern Nibiru demonstrated in 2013 at a different layer. When organizational intelligence is encoded into the platform, output quality goes up and cycle time collapses.
The Thread Is Documented
This is not something I figured out by looking backward.
In 2014 I published the Nibiru architecture with screenshots. In 2015 I wrote that flexible platforms create snowflakes and the only solution is encoding your business logic into an abstraction layer. In 2018 I wrote that infrastructure teams fail because they run projects instead of building products. In 2025 I built OutcomeOps.
Same sentence every time: make the right path the easy path.
The commit log is the proof. 173 commits in awsdeploy starting August 2012. 2,607 commits in Nibiru v2 across a team of seven. The code is still on GitHub. The screenshots from 2014 are still live. The blog posts from 2015 and 2018 are still up.
OutcomeOps is the same idea running one abstraction higher, with a 2026 context window and AWS Bedrock instead of Puppet.
The organizations that internalize this pattern are going to compound their advantage for the next decade. The ones waiting to see how the AI tools mature will look back at 2025 the same way the manual provisioning teams looked back at 2013.
Organizational intelligence always wins. It just needs a platform to live in.
OutcomeOps deploys into your AWS account via Terraform. Your data, your context, your infrastructure. If you are an engineering leader who recognizes this pattern — what's the biggest friction you're seeing with AI code generation in your org? I'd like to hear it.
OutcomeOps: The Future of AI Engineering
Opens Substack in a new tab to confirm. No spam — unsubscribe anytime.
Enterprise Implementation
The Context Engineering methodology described in this post is open source. The production platform with autonomous agents, air-gapped deployment, and compliance features is available via enterprise engagements.
Learn More